MyCAT 代码分析
更新日期:
本文以 MyCAT 2.0-dev 代码为例,分析 MyCAT SQL执行部分的代码。
系统启动
系统的入口方法在 io.mycat.MycatStartup 中的 main 方法,主要代码如下两行,
MycatServer 是一个单例类,所以,等于直接调用 MycatServer 中的 startup() 方法。startup() 方法中,除去一些打印 log 的代码,主要初始化了一些系统参数(如网络、datasource)和连接池,重要的代码是以下几行,
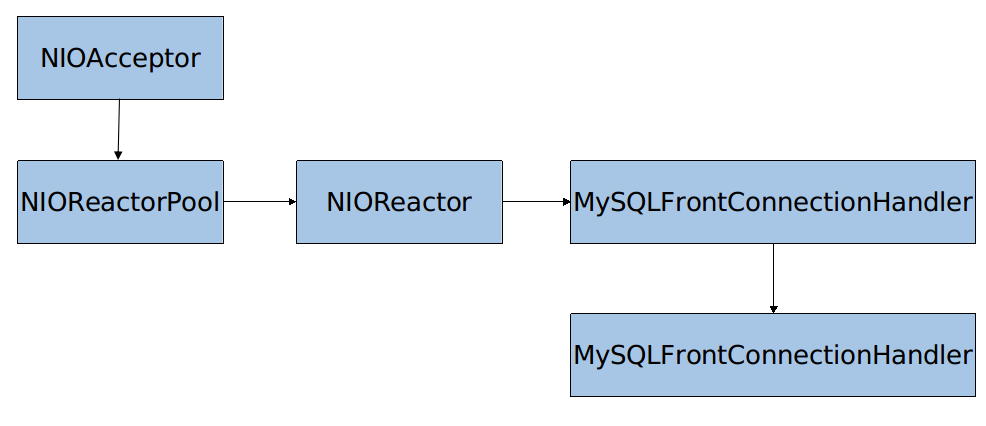
首先初始化了一个 NIOReactor 的线程池 NIOReactorPool 和一个 MySQL 连接的工厂类 MySQLFrontConnectionFactory,然后以这两个为参数,构造了 NIOAcceptor 类,并在主线程中启动 start()。其中,NIOReactorPool 主要包含一个 NIOReactor 的数组,每个数组都是一个线程对象,处理每一个客户端网络连接,该类在初始化完成的时候,已经调用了 reactor.startup(),启动了所有 NIOReactorPool 中的所有线程。NIOReactorPool、NIOReactorPool 和 NIOReactor 这3个类组成了 MyCAT 处理客户端连接的几乎全部代码。MyCAT 主要使用 NIO (java.nio)网络模型,对高并发请求有更好的处理,但是其程序结构中有很多回调函数的写法,不是很容易理解和掌握。另外,MySQLFrontConnectionFactory 是工厂类,主要用于生成处理连接的 MySQLFrontConnection 类(该类继承自 GenalMySQLConnection,GenalMySQLConnection 继承自 Connection)。这些类都是之后代码分析中非常重要的类。
至此,主线程已经完成初始化,并启动了 NIOAcceptor,NIOAcceptor 继承了 Thread,下面的代码入口在 NIOAcceptor.run()。
处理网络连接
处理网络连接的入口在 NIOAcceptor.run(),该方法中启动了一个无限循环,主要调用了该类中的 accept() 方法,方法的主要代码有以下几行,
先是调用 serverChannel.accept(),这是 NIO 的调用,用于接受一个新的连接 channel,然后设置连接为 nonblocking 模式。然后以新连接 channel为参数创建 Connection,然后,从线程池中获取一个 NIOReactor 线程,并调用 postRegister(c),将 Connection 注册在该线程中,所有连接的请求都调用该 Connection 中的方法来处理。由于 NIOReactor 线程已经启动,所以会直接调用其中的 run() 方法。而实际上,NIOReactor 中有一个内部类 RW,线程调用的是 RW.run()。
注意,这里通过工厂类创建的 Connection 实际上是 MySQLFrontConnection 类,因为工厂类是传入的 MySQLFrontConnectionFactory 类。严格来说,该工厂类在设计模式上应该属于抽象工厂,其父类 ConnectionFactory 会通过 Connection make(SocketChannel channel) 方法创建 Connection类,该方法代码如下,
该方法中,依次调用 makeConnection() 和 setHandler() 这两个抽象方法用于创建连接,并将请求处理类设置为 NIOHandler,而子工厂类中,需要实现这两个方法用于创建连接实例。在 MySQLFrontConnectionFactory 类中,makeConnection() 方法创建了 MySQLFrontConnection,NIOHandler 设置为初始化该工厂类时的 MySQLFrontConnectionHandler。这两个类是处理 sql 请求的主要类,关于这两个类,后文再详细描述。
在 RW.run() 方法中,主要有一些 NIO 相关的调用,最重要的调用是 con.asynRead();,该方法比较简单,重要代码如下,
先是将网络数据读入到 readBuffer 中,然后调用 onReadData()。在 onReadData() 方法中,有很多读入字节的代码,重要的代码是调用 handle(readBuffer, offset, length); 方法,实际上是调用 NIOHandler 的 handle() 方法,也就是 MySQLFrontConnectionHandler 类的 handle() 方法。
至此,MyCAT 处理网络连接部分的代码已经完成,对于网络请求的数据已经完成读入到 Buffer,之后的代码入口在 MySQLFrontConnectionHandler.handle()。
处理 SQL 请求
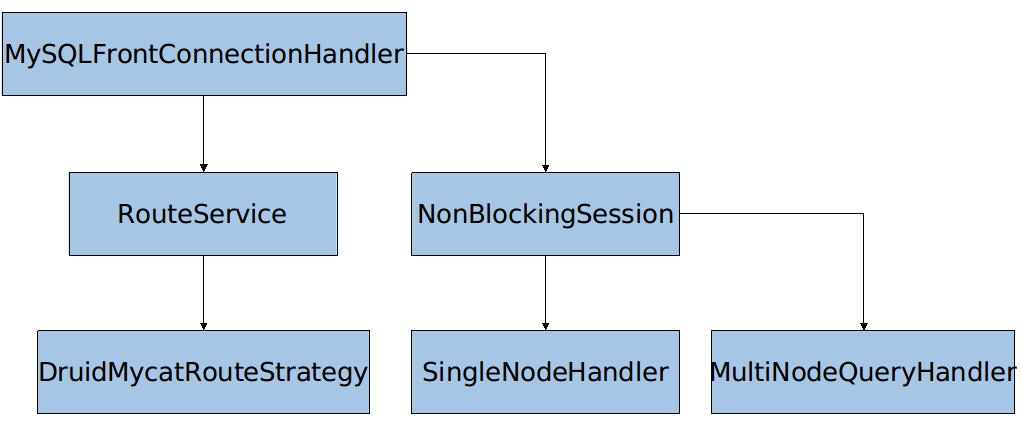
处理 SQL 请求的入口在 MySQLFrontConnectionHandler.handle(),其中,根据 Connection 的状态,分别调用了 doConnecting 和 doHandleBusinessMsg,doHandleBusinessMsg 方法主要用来处理 SQL 请求。该方法中,处理一般 SQL 的代码是,
其中的 source 是之前的 MySQLFrontConnection 类,也就是执行其中的 query(byte[]) 方法,该方法中做了一些字符处理的操作,最主要的应该是 sql = mm.readString(charset); 这一行,用于处理字符集。最后调用了 query(String) ,该方法先执行了 SQL 的检查,最后开始真正执行 SQL,如下,
其中,用于执行一般 SQL 查询的是 SelectHandler.handle(sql, this, rs >>> 8);,该方法中,对 SQL 的类型做了一些判断,一般的 SQL 会执行最后一行的 c.execute(stmt, ServerParse.SELECT);(该方法属于 MySQLFrontConnection 类)。该方法中会检查数据库 Schema 的配置,最后调用 routeEndExecuteSQL(sql, type, schema);,该方法对 SQL 进行路由(即寻找执行 SQL 的数据库),然后执行 SQL(PS:我猜测方法名应该是取错了,应该是 routeAndExecuteSQL,而不是 routeEndExecuteSQL)。其中重要的代码如下,
前一个调用是将 SQL 路由到数据库,后一个调用是执行解析之后的 SQL,这两部分的代码都比较独立,可以分别解析。其中,session 是 NonBlockingSession 类,该类有两个比较重要的 field,
source 是前端连接,表示 MyCAT 面向客户端的连接,target 是后端连接,表示若干个连接到后端 MySQL 上的连接。
SQL 路由
SQL 路由的入口在 RouteService.route(),该方法先判断 SQL 路由是否有之前解析的结果,如果有直接使用;否则,开始解析 SQL。解析 SQL 的时候,会先判断该 SQL 有没有 Hint,如果有,按Hint中指定路径进行解析;否则,调用 RouteStrategyFactory.getRouteStrategy().route() 方法寻找合适的路由。RouteStrategyFactory 是一个路由策略的工厂类,目前,MyCAT 中只有一个基于 druidParser 的路由策略,对应 DruidMycatRouteStrategy 类。
MyCAT 中的 SQL 路由相关的类有:RouteResultset 用于保存路由结果;RouteStrategyFactory 是路由工厂,生成 RouteStrategy;RouteStrategy 是路由类最顶层的接口,其中只有一个 route() 抽象方法;AbstractRouteStrategy 是路由类的抽象类,实现了 RouteStrategy,定义了路由的基本步骤,返回 RouteResultset,其中,最重要的抽象方法是 routeNormalSqlWithAST,基于 AST 树来寻找路由;DruidMycatRouteStrategy 继承了 AbstractRouteStrategy,实现了 AbstractRouteStrategy 中的所有抽象方法。
DruidMycatRouteStrategy 的 routeNormalSqlWithAST 方法中,有以下一些比较重要的调用,
由于 MyCAT 使用的是第三方的 Druid SQL 解析工具,因此要在 Druid 解析器中加入自己的处理,这里,Druid 解析器使用了 visitor 模式,MycatSchemaStatVisitor 类继承 MySqlSchemaStatVisitor 并实现了其中的多个重载的 visit 方法,在调用 druidParser.parser() 的时候进行计算。routeNormalSqlWithAST 方法的最后,解析之后的 SQL 被路由到若干个分片节点上,并保存在 RouteResultset 中,然后返回。
SQL 执行
SQL 执行的入口在 NonBlockingSession.execute(),该方法主要分两个分支,单节点 SQL 执行和多节点 SQL 执行,分别是 SingleNodeHandler 和 MultiNodeQueryHandler 两个类,在每个分支中,依次调用了 setPrepared() 方法和 execute() 方法。
对于单节点情况,SingleNodeHandler.execute() 先获取该单节点的 MySQL 后端连接,然后调用 _execute(conn),在 _execute(conn) 中,主要代码如下,
先将 SQL 返回的回调类设为 SingleNodeHandler,也就是自己,然后调用后端连接 BackendConnection 类的 execute 方法,真正的执行 SQL。对于后端是 MySQL 数据库的时候,实际上使用的的是 MySQLBackendConnection 类,该类的 execute 方法调用了 synAndDoExecute,并在 synAndDoExecute 中调用了 sendQueryCmd,向 MySQL 发送 SQL 请求。对于 SQL 的返回,是实现 ResponseHandler 接口来实现的,该接口定义了不同的 SQL 返回处理方法。
对于多节点的情况,MultiNodeQueryHandler 类的基本流程和 SingleNodeHandler 一样,不同之处有几个地方。一个是,在 execute() 方法中,对每一个节点分别调用 _execute(conn) 执行 SQL;还有一个是,回调的接口实现要更加复杂一些,例如,rowEofResponse 接口的实现中,调用了 DataMergeService,用于合并多个数据库上查询返回的结果。
总体结构图
总体大致的结构图如下,比较粗略,