Postgres的数据模型(翻译稿)
更新日期:
Postgres的数据模型(翻译稿)1
Lawrence A. Rowe Michael R. Stonebraker
计算机科学学院,EECS系, 加州大学伯克利分校,CA 94720
摘要
本文描述了Postgres数据模型的设计。数据模型是一个关系模型,并扩展了抽象数据类型,包括用户自定义的操作符和过程、类型过程的关系属性、以及属性和方法的继承。这些机制可以用来模拟各种语义和面向对象数据模型的结构,包括聚合和泛化、具有共享子对象复杂对象、和引用其他关系中元组的属性。
1 引言
本文介绍了Postgres的数据模型,这是一个由加州大学[StR86]开发的下一代可扩展的数据库管理系统。数据模型是基于Codd[Cod70]发展的扩展关系模型思想,其中包含了可用于模拟各种语义数据建模结构的一般机制。该机制包括:1)抽象数据类型(ADT)2)类型过程的数据,和3)规则。这些机制可以被用来支持复杂的对象或为面向对象的编程语言[Row86]实现共享对象层次结构。大多数的这些思想在其他研究也有出现[Ste84,Sto85,Sto86a,Sto86b]。
我们已经发现,没有直接支持的某些语义结构可以被很容易地添加到系统中。因此,我们更改了一些数据模型和查询语言的语法,如下文所述。这些改动包括提供主键、数据和过程的继承、以及引用其他关系中元组的属性。
本文的主要贡献是证明继承可以被添加到一个关系数据模型,并且对模型只有很温和的一些更改和系统实现。我们从这个结果得出的结论是,面向对象数据模型中提供的主要概念(例如:结构化的属性类型、继承、统一类型属性、以及共享子对象的支持)可以清洁、有效地支持可扩展的关系数据库管理系统。
用于支持这些机制的功能是抽象数据类型和类型过程的属性。
在本文的其余部分将介绍Postgres的数据模型,其结构安排如下:第2节介绍的数据模型。第3节描述的属性类型系统。第4节描述了如何用户自定义过程扩展查询语言。第5节比较该模型与其他数据模型。第6节总结全文。
2 数据模型
数据库是由一组关系组成集合,这些关系包含了真实世界实体(如文件和个人)或管理(例如,著作权)的元组。一个关系具有表示实体特性的固定类型的属性、关联(例如:文档的标题)和主键。属性类型可以是原子的(如整型,浮点型,或布尔型)或结构化的(例如:数组或过程)。主键是关系的一系列属性,当这些关系结合在一起时,唯一地标识每个元组。
我们用一个简单的大学数据库来说明该模型。下面的命令定义了表示人的关系:
该命令定义了一个关系,并创建了用于存储元组的结构。
关系的定义可以根据需要指定一个主键,其它关系可从该主键继承属性。主键是属性的组合用于唯一标识每个元组。主键可以通过key子句指定,如下:
元组必须对所有主键属性都有值。主键的规格可任意包括一个用于比较两个元组的操作符的名称。例如, 假设一个关系有一个主键,其类型是一个用户定义的ADT。如果一个类型是box的属性是主键的一部分,比较操作符必须被指定,因为不同box操作符可以用来区分数据条目(例如,面积等于或box相等)。下面的例子 显示了包含类型为box属性的关系的定义,它使用面积等于这个操作符(AE),以确定主键值相等:
数据继承可以用inherits子句来指定。举个例子,人在大学这个数据库中表示为雇员和/或学生,并且不同的属性可用来定义每个不同的类别。每个类别的关系,包含了人的属性和该类别的特定属性。这些关系可以通过复制人在每个关系定义中的属性或从人的定义中继承这些属性来定义。图1显示了可用于共享属性定义的关系和继承层次结构。定义除去上述已定义的人这个关系之外的关系的命令是:
除非属性在定义中被覆盖,一个关系继承其父关系的所有属性。例如,员工关系继承人的属性:姓名、出生日期、身高、体重、地址、城市和国家。主键规格也被继承了,因此名字也是员工的主键。
关系可以从一个或多个的父关系中继承属性。例如,学生员工(STUDEMP)继承学生和员工的属性。相同的属性名称从多个父关系(例如:学生员工(STUDEMP)从员工和学生继承状态(Status))时,可能会发生继承冲突。如果被继承的属性具有相同的类型,则包含在关系中的属性与类型被定义。否则,该声明是不允许的2。

图1:关系层次结构(译注:原文这里没有图,所以放一张我家宝宝的照片)
Postgres查询语言是QUEL[HSW75]的广义版本,称为POSTQUEL。对QUEL在几个方向做了拓展。首先,POSTQUEL有一个from子句来定义元组变量,而不是用range命令。第二,任意关系-值表达式在QUEL中,可能会出现在任何关系名可以出现的地方。三,传递闭包和execute命令已被添加进来[Kue84]。最后,POSTGRES保留历史数据,因此POSTQUEL允许将查询执行在过去的数据库状态上或数据库上任何时间的任何数据。本节的齐豫部分将会讨论这些扩展中。
在from子句添加到语言后,查询中的元组变量定义可以很容易地在编译时确定。POSTGRES需要这种能力,因为它会在用户的请求时,编译查询并保存在系统目录中。在下面的查询中,我们用from子句演示,列出所有大二的学生员工:
from子句指定元组的集合表示元组变量的范围。在这个例子中, 元组变量SE的范围是设定再学生员工这个集合上。
具有相同名称的默认元组变量定义为在引用目标列表中或查询的where子句中的每个关系。例如,上面的查询可以被写成:
请注意,该属性IsWorkStudy是一个布尔值属性,因此它并不需要一个明确的值检验(例如,STUDEMP.IsWorkStudy=‘‘true’’)。
元组变量范围的元组集合可以是已命名的关系或关系表达式。例如,假设用户想要从数据库检索所有住在伯克利的学生,而不管他们是否是学生或学生员工。这个查询可以写成如下形式:
''*''操作符指定的关系是通过已命名关系(例如:STUDENT)和所有从这些关系中继承属性的关系的组合而形成的。
如果''*''操作符不使用时,查询只检索学生关系中的元组(例如:学生,而非学生员工)。在很多支持继承的数据模型中,关系名默认为在继承层次结构上的关系的组合(例如:上述描述学生的数据)。我们选择不同的默认值,因为这涉及组合的查询会比涉及单个关系的查询要慢。通过强制用户显示使用''*''操作符来请求组合上的查询,他会意识到这个成本。
关系表达式可以包括其他集合运算符:并($\cup$)、交($\cap$)、差($-$)。例如,下面查询检索那些是学生或员工的人,但却不是学生员工的人的名字:
假设一个元组没有在查询中引用的其他属性。如果参照是在目标列表中,返回的元组将不包含该属性3。如果引用在限定中,含限定子句是''false''。
原先的POSTQUEL还提供了一套比较操作符和关系构造器,可以用于比以往的查询语言更容易地写一些困难的查询。例如,假设学生有几个专业。对此类数据的自然展现是定义一个单独的关系:
其中Sname是学生的姓名和Mname是专业。在这种展现中,如下的查询获取那些和Smith有相同专业的学生的名字:
括在大符号('' {...}'')内的表达式是关系构造器。
关系构造器4的一般形式为
它指定了和如下查询相同的关系
注意,外部查询(例如,上述查询中的M1)中所定义的元组变量可以用于关系构造器,但在关系构造器中定义的元组变量不能在外部查询中使用。一个元组变量的关系构造器的重定义创建一个不同的变量,正如块结构化程序设计语言(如PASCAL)一样。关系值表达式(包括将在下一节中描述的类型过程的属性)可以在查询中的任何地方使用。
数据库更新可以用常规的更新命令指定,如下列所示:
所有更新命令都使用延迟更新的语义。
POSTQUEL支持QUEL[Kue84]中开发的传递闭包的命令。''*''命令继续执行,直到检索(例如,retrieve)不到任何元组或更新(例如,append、delete或replace*)。例如,下面的查询将创建关系包含为史密斯工作的所有员工:
此命令继续执行retrieve-into命令,直到对SUBORD关系改变已经全部完成。
最后,POSTGRES保存关系中已删除或已修改的数据,这样的查询可以在历史数据上执行。例如,下面的查询查找在1980年8月1日住在伯克利(Berkeley)的学生:
在关系名之后的括号内指定的数据用于指定特定的时间。日期可以指定为不同的格式,甚至可以包括一天中的某个时间点。上述查询只检查不是学生员工的学生。如果要检索集合中的所有学生,from子句可以改为:
查询也可以在当前关系中的所有数据上或在关系上的过去任意时间(即,所有数据)执行。下面的查询检索曾经住在 伯克利的学生:
符号'[]'可以附加到任何关系名之后。
查询也可以指定在关系中某段给定时间段的数据上。时间段是通过给定一个开始和结束时间来指定的,例如,以下查寻检索在1980年8月的任何时间住在伯克利的学生:
缩写符号支持在关系中的所有元组到特定日期(例如,STUDENT[,‘‘August 1, 1980’’]),或从一些日到现在(例如,STUDENT[,‘‘August 1, 1980’’,])。
POSTGRES的默认是保存所有数据,除非用户明确要求清除数据。数据可以从一个特定时间点之前清除(例如,1987年1月1日之前)或之前的某个时间段(例如,半年之前)。用户也可以要求清除所有历史数据,这样关系中只有的当前数据被存储下来。
POSTGRES还支持关系的版本。关系的版本可以从关系和快照创建。版本可以通过指定基(base)关系来创建,如下图所示命令
创建一个名为MYPEOPLE,从人的关系而得的版本。版本中的数据可以像关系一样做检索和更新。版本的更新没有修改基关系。而,更新基关系会传播到版本,除非值已经被修改。例如,如果乔治的生日在MYPEOPLE已经被修改,改变他在PEOPLE中生日的replace命令就不会传播到MYPEOPLE。
如果用户不希望基关系的更新传播到版本,他可以创建一个快照的版本。快照是关系当前内容复制[AdL80]。一个快照的版本由以下命令创建:
快照版本可以直接通过向版本下更新命令进行更新。但是,基关系的更新不会传播到的版本。
merge命令提供,将多个修改合并到一个版本,并写回基关系的功能。该命令的一个例子是
将合并在YOURPEOPLE上的更新回到PEOPLE。merge命令采用半自动过程来解决基关系上的更新和版本上的更新之间的冲突[Gae84]。
本节中描述的POSTQUEL中的大多数数据定义和数据操作命令。那些没有描述的命令是用于定义规则、只影响系统的性能(例如,define index和modify)的实用命令、其他各种实用工具命令(例如,destroy及copy件)。下一节介绍关系属性的类型系统。
3 数据类型
POSTGRES提供一系列原子和结构化类型。预定义的原子类型包括:INT2,INT4,float4,float8,bool,char和date。提供标准的算术和比较操作符用于数字和日期数据类型,标准字符串运算符和比较操作符用于字符数组。用户可以使用抽象数据类型(ADT)定义工具来添加新的原子类型来扩展系统。
所有的原子数据类型在系统中都定义为ADT。ADT是通过指定类型名称、内部表示的字节长度、外部表示到内部表示的值转换过程、内部表示到外部表示的过程、和默认值来定义。命令
定义了系统中预定义的类型int4。CharToInt4和Int4ToChar是传统编程语言(如C)中实现的过程,并使用在第4节描述的命令定义到系统中。
ADT上的操作符是通过指定操作数的数量和类型、返回类型、操作的优先级和结合律、以及实现它的过程来定义。例如,命令
定义了加法操作符。优先级由数字指定。数字越大表示优先级越高。预定义的操作符具有与图2所示的优先级,这些优先级可通过改变操作符定义而改变。结合律是左或右取决于期望的语义。本例用符号+定义了一个操作符。操作符也可以通过如下标识符来表示。
另一个ADT定义的例子如下,是用来定义一个表示盒子(box)的ADT:
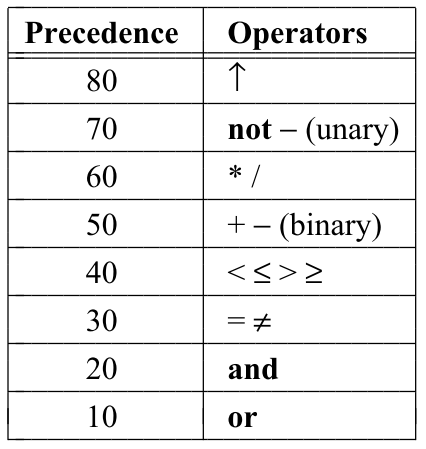
图2:预定义运算符的优先级。
盒子的外部表示是一个包含表示两点的字符串,这两点表示盒子的的左上角和右下角。在这个表示中,常量
$$''20,50:10,70''$$
描述了一个盒子,其左上角为(20,50)和右下角为(10,70)。CharToBox需要类似这样的字符串参数,并返回一个盒子的一个16字节表示(例如:每个x或y坐标用4字节)。 BoxToChar是CharToBox的反向操作。
比较操作符可以在ADT上定义,在访问方法中使用或在查询中被优化。例如,定义
定义盒子上的操作符''面积等于(AE)''。除了关于操作符本身的语义信息,这个规范包括POSTGRES用于构建索引来用这个操作符优化查询的信息。例如,假设图片(PICTURE)关系是通过如下来定义
并且执行的查询是
AE操作符的排序(Sort)属性说明改过程可以用于排序关系,如果''合并-排序(merge-sort)''连接策略被用来实现查询。它也可以用于在盒子类型的属性上建立一个有序索引(如B-树)时指定该过程。哈希(Hash)属性表示这个操作符可以用来在盒子属性上建立哈希索引。注意,任一类型的索引都可以被用来优化上述查询。限制(Restrict)和联合(Join)属性指定过程,让查询优化器来调用用于分别计算涉及到操作符的子句的限制和联合的选择性(Selectivity)。这些选择性属性指定返回0.0和1.0之间的某个浮点值的过程,该浮点值表示对给定操作符上属性的选择性。最后,否定(Negator)属性指定的过程用来当查询谓词要求操作符取反时比较两个值,如
定义操作符(define operator)命令还可以指定过程用于查询谓词包含不可交换的操作符的情况。例如,对于''面积小于''(area less than, ALT)交换器过程实现了''面积大于或等于''(area greater than or equal, AGE)过程。使用这些属性的详细信息在其他地方给出[Sto86b]。
提供类型构造器来定义结构化类型(例如,数组和过程)用于表示复杂的数据。数组(Array)类型构造器可以用来定义一个可变或固定大小的数组。固定大小的数组通过指定元素类型和数组上限大小来声明,如下
它定义了25个字符的数组。数组元素由索引从1到25的整数这个属性来引用(例如,''PERSON.Name[ 4 ]''引用人名中的第四个字符)。
可变大小数组可以通过在类型构造器中省略上限来指定。例如,可变大小的字符数组是由''char[]''来指定。可变大小的数组的引用可以通过索引从1到当前最大上限的整数这个属性。预定义的函数size返回当前的上限。 POSTGRES并没有强行对可变数组的大小做限制。它提供内置函数来追加数组,以及获取数组片段。例如,两个字符数组可以使用串联操作符(''+'')来追加,名x的属性中包含第2到15个字符的数组片段可以由表达式''X[2:15]''获取。
第二种类型构造器允许类型过程的值存储在属性中。过程值由POSTQUEL命令的序列来表示。类型过程属性的值是关系,因为这是一个retrieve命令返回。此外,该值可包括不同关系(如,不同类型)的元组,因为由两个retrieve命令组成的过程返回这两个命令的组合。我们称包含不同元组类型的关系为多元关系(multirelation)。 POSTGRES编程语言
接口提供了类似游标的机制,称为portal,从多元关系获取值[StR86]。但是,它们不能存储在系统(即,只有关系可以存储)。
系统提供两种过程类型构造器:变量和参数。变量过程类型允许不同的POSTQUEL过程存储在每个元组,而参数过程类型在每个元组中存储类型不同的相同过程。我们将通过展示表示学生专业的另一种方法来说明变量过程类型的作用。假设系(Department)关系由如下命令定义:
因而,学生的专业可以通过在学生关系中检索检索相关系元组的过程来表示。专业属性的声明如下:
数据类型postquel代表过程类型。专业(Majors)中的值是获取表示学生辅修专业学院的关系元组的查询。下面的命令追加一个拥有数学和计算机科学双主修专业的学生进数据库数据库:
引用主修专业属性的查询返回一个包含POSTQUEL命令的字符串。然而,我们提供了两个符号来执行查询并返回结果,而不是定义。首先,如下所示嵌套点标记隐式执行查询
这打印学生姓名和专业的名单。查询专业的结果是隐式连接了由目标列表的其余部分指定的元组。换句话说,如果一个学生有两个主修专业,这个查询将返回两个Name属性重复的元组。隐式连接的执行以保证了关系的返回。
执行查询的第二种方法是使用execute命令。例如,查询
返回对所有Smith的专业包含DEPARTMENT元组的关系。
参数化的过程类型用于当存储在属性中的查询对每个元组是近乎相同的。查询参数可以从元组中的其他属性或被明确地指定。例如,假设一个在STUDENT中的属性是
代表学生目前的课程列表。对入学情况,给定如下定义:
比尔(Bill)的课程列表可以通过如下查询检索
除去指定学生名的常量之外,该查询对每个学生都相同。
参数化过程类型可以定义表示这样的查询,如下所示:
美元符号符号(''$'')是指查询所存储的元组(即,当前元组)。每个这种类型(即查询)的实例的参数就是实例存储在的元组的Name属性。这种类型用在create命令中,如下
定义一个属性,表示该学生目前的课程列表。这个属性可以用在查询中返回的学生和他们正在学习的课程的列表:
注意,对于一个特定的STUDENT(学生)元组,查询中的表达式''$Name''指的是那个学生的名字。符号'$'可以被看作是一个元组变量绑定到当前元组。
参数化的过程类型是非常有用的类型,但有时候实在不方便显式地存储该参数到关系的属性中。因此,提供一个符号来允许参数存储在过程类型值中。这种机制可以用于模拟引用其他关系的元组的属性类型。例如,假设你想引用一个如上述定义的DEPARTMENT关系中的元组。这个类型可以如下定义:
关系名称可用于类型名称,因为关系,类型和过程都有各自的命名空间。给定元组的唯一对象标识符(object identifier, oid),在类型DEPARTMENT(系)中的查询会检索特定的系元组。每个关系都有一个隐式的已定义属性称为oid,包含元组的唯一标识符。OID属性可以被访问,但不能被用户的查询更新。oid的创建和维护值都是由POSTGRES存储系统[Sto87]完成的。这个过程类型的形式参数就是对象标示符的类型。参数在定义中通过''$n''被引用,其中n是参数数字
当值被分配给DEPARTMENT类型的属性,就提供一个实际参数。例如,COURSE(课程)关系就可以被定义用于表示具体课程有关信息,包括提供课程的系。创建命令是:
属性Dept代表提供课程的系。下面的查询增加一个课程进数据库:
在目标列表中被调用的Department过程是通过''define type''命令隐式定义的。通过给定和形式参数类型兼容的实际参数,它构造了一个指定类型的值,在这个例子中,类型是int4。
表示特定关系中元组引用的参数化过程是很常用的,因此,我们计划为他们提供自动支持。首先,每个创建的关系需要有一个表示元组的引用的隐式定义的类型,如上面的Department类型。第二,它有可能直接为元组引用属性分配一个元组变量。换句话说,分配给属性Dept,就是上述查询中的
可以写为
参数化过程的类型也可以用于实现在任意关系中引用一个元组的类型。类型的定义是:
定义类型的元组(字符[],INT4)是
第一个参数是该关系的名称,第二个参数是关系中所需的元组的OID。实际上,这种类型定义了一个任意元组的引用到数据库中。
过程类型的元组可以用来创建表示帮助筹措资金人的关系:
因为志愿者可能是学生,雇员,或既不是学生也不是员工的人,该属性Person必须包含一个引用,可以引用任意关系中的元组。以下命令会将所有的学生加入到VOLUNTEER(志愿者):
预定义的函数relation返回元组变量S绑定的关系的名称。
类型tuple(元组)也是特例,使其更方便。元组是一个预定义的类型,并且它可能直接向类型的属性分配的元组变量。因此,分配上面提到的Person
可写为
我们预计,随着我们在POSTGRES程序的获得更多经验,更多类型的可能成为特例。
4 自定义程序
本节介绍了添加用户自定义的程序到POSTQUEL的语法构成。用户自定义过程用传统的编程语言编写,用于实现ADT操作符,或将前端应用程序的计算转移到后端数据库系统过程。
转移计算到后端打开了DBMS的预先计算包含计算的查询的可能性。例如,假设一个前端应用程序需要从数据库中获取表单的定义,并构建一个主内存中的数据结构,这样运行时表单系统可以用于将数据项展示在终端屏幕上的表单中。传统的关系型数据库的设计将表单组件(例如,标题、和不同类型的字段定义,如标量字段,表字段和图形字段)存储在不同的关系中。示例数据库设计是:
从数据库中获取表单的查询必须每个表至少执行一个查询,并且通过排序返回的元组来构造主内存中的数据结构。对交互式应用,此操作必须在不到两秒钟内完成。传统的关系型数据库管理系统的不能满足这样的时间限制。
我们解决这个问题的方法是把构建主内存数据结构的计算转移到数据库的过程中。假设过程MakeForm对滚定的表单名产生数据结构。使用上面定义的参数化过程类型机制,通过这个过程的计算,属性可以添加到存储表单表示的FORM关系中。该命令如下
定义了过程类型,并添加一个属性到FORM关系。
这种表示的优点在于POSTGRES可以预先计算过程类型属性的答案,并将其存储在元组。通过预先计算主内存数据结构的表示,该表单可以通过单一元组检索从数据库中获取:
获取和显示表单的实时约束可以很容易满足,如果所有过程必须做的是单一元组检索来获取数据结构,并调用库函数来显示它。这个例子说明了将应用过程的计算转移到数据库过程的优势(即构建主内存数据结构)。
过程通过指定的参数的名称和类型、返回类型、编码的语言、以及代码和对象存储的位置来定义到系统中。例如,该定义
定义了一个过程AgeInYears,提供一个日期值参数,返回人的年龄。参数和返回类型是使用POSTGRES类型指定的。当程序被调用时,它使用类型在POSTGRES中的内部表示来传递的参数。我们计划允许过程可以用几种不同的语言,包括C和Lisp,来编码,这两种语言也是用来实现系统的语言。
POSTGRES存储过程的有个信息在系统目录中,然后,在查询调用时,动态加载对象代码。下面的查询使用AgeInYears过程来获取示例数据库中所有人的名字和年龄:
用户自定义过程也可以使用元组变量参数。例如,下面的命令定义了一个叫做Comp的过程,接受一个员工的元组,并根据一些公式计算员工的补偿,公式涉及到元组中的几个属性(例如,员工的身份,职务和薪水):
回想一下,参数化过程类型对每个关系自动定义,所以类型EMPLOYEE(员工)代表EMPLOYEE关系中元组的引用。这个过程在下面的查询中调用:
实现此过程的V函数传入了一个数据结构,包含名字、类型、以及元组中的属性的值。
用户自定义过程也可以传入其他关系中的元组,只要该关系继承了声明为过程参数的关系属性。例如,对员工关系定义的Comp过程可以传入STUDEMP元组,如下
因为STUDEMP继承了EMPLOYEE的数据属性。
使用关系元组作为参数的过程必须一种自描述的数据结构传入参数,因为过程可以传入不同关系的元组。从其他关系继承的属性可以在关系中有不同位置。此外,对同样的类型名传入的数值可能是不同的类型(例如,继承属性的定义可能被另一个类型覆盖)。自描述数据结构是一个参数列表,元组中的每个属性都需要传入,使用以下结构
过程代码会搜索列表中找到想要的属性。提供例程库将会对程序员隐藏此结构。库包含例程用于对给定属性名获取属性的类型和值。例如,下面的代码获取的Birthday(生日)属性的值:
可变参数列表的问题出现在所有面向对象编程语言中,并使用了相似的解决方案。
过程继承的模型与面向对象编程语言[StB86]中的方法几乎相同。过程继承使用的数据继承架构和相似的继承规则,除了提供了继承冲突时选择过程的规则。例如,假设Comp过程在STUDENT和EMPLOYEE上定义。其中,第二个过程的定义可能是:
当上午中的STUDEMP上的查询被执行时会发生冲突,因为系统不知道要调用哪一个Comp方法(即,一个EMPLOYEE上的方法和一个STUDENT上的方法)。
调用的过程是从传入元组的过程中选出来的,元组来自于实际参数STUDEMP指定的关系,或从其他关系中继承的属性。(例如,PERSON、EMPLOYEE、和STUDENT)。
每个关系都有一个继承优先列表(IPL),用于解决冲突。列表的构成是由关系本身开始,并从第一个inherits子句中指定的关系开始做深度优先搜索沿继承层次结构向上。例如,对STUDEMP,inherits子句是
其IPL是
PERSON出现在EMPLOYEE之后,而不是STUDENT之后,在深度优先搜索中,因为STUDENT和EMPLOYEE从PERSON继承了属性(见图1)。换句话说,所有层次结构都被删除了,除了在深度优先排序中最后出现的关系5。
当过程被调用,并传入元组作为第一个参数,当在参数的IPL中含参数的过程按顺序被找到,实际调用的过程是同名过程中第一个找到的定义。在上面的例子中,为STUDENT定义的Comp过程被调用,因为没有名为Comp的方法定义在STUDEMP,而STUDENT是IPL中的下一个关系。
选择过程规则的实现是相对容易的。假设两个系统目录如下定义:
其中PROCDEF对每个定义的过程的都有入口,IPL为所有关系维护优先级列表。PROCDEF中的属性代表了过程的名称,参数类型名称,金额存在另一个目录中的程序代码的唯一标识符。IPL中的属性代表关系,关系的IPL入口,和IPL中入口的序列号。有了这两个目录,为如下调用找到正确的过程的查询
是6
这个查询可以预先计算,以加速过程的选择。
总之,支持过程继承所需要的主要变化是1)允许元组作为参数传给过程,2)定义为可变参数列表的表示,和3)实现过程选择机制。这个关系模型的扩展相对简单,只需要对数据库管理系统实现做少量的改动。
5 其他数据模型
本节比较POSTGRES的数据模型和语义,功能和面向对象数据模型。
语义及功能数据模型[Dae85,HaM81,Mye80,Shi81,SmS77,Zan83]不提供通过本文描述的模型所提供的灵活性。它们不能轻易表示含不确定结构(例如,包含不同类型共享子对象的对象)的数据。
面向复杂对象[HaL82,LoP83]的建模思想不能处理包含多个共享子对象的对象。POSTGRES使用过程来表示共享子对象,对共享子对象的类型没有限制。此外,嵌套点(nested-dot)标记允许方便地访问选定的子对象,这是这些系统没有表述的特性。
几个已有的提议支持包含非第一范式关系[Bae86,Dae86,Dee86]的数据模型。 POSTGRES的数据模型可以用来支持包含过程类型的非第一范式的关系。因此,POSTGRES似乎包含这些提议功能的一个超集。
面向对象的数据模型[Ane86,CoM84]有建模结构,以应对不确定结构。例如,GemStone支持联合类型,其可以被用来表示具有不同类型的子对象[CoM84]。子对象的共享是通过存储子对象为不同的记录并用指针链连接它们和父对象来表示。预先计算的过程值,在我们看来,使POSTGRES性能可以与用指针链的方法相媲美。当一个对象是由大量的子对象构成时,指针链的性能问题将是最明显的。POSTGRES将避免这个问题,因为该指针链表示为关系,系统可以使用所有可用的查询处理和存储结构技术来代表它。因此,POSTGRES使用一种不同的方式来支持相同的建模功能,和一个可能有更好性能的实现。
最后,Postgres的数据模型,可以称得上是面向对象的,尽管我们不喜欢使用这个词,因为很少有人认同它到底是什么意思。该数据模型,作为一种面向对象的模型,提供相同的功能,但它这样做却不用丢弃关系模型,也不必引入新的令人疑惑的术语。
6 小结
Postgres的数据模型使用抽象数据类型、类型过程的数据,和继承的思想来扩展关系模型。这些思想可以用来模拟各种语义数据建模概念(例如,汇总和归纳)。此外,同一思想可以用于支持包含不可预测的组合和共享子对象的复杂对象。
参考文献
日志
- 2014.08.03,翻译第一稿完成,感谢google,不要问我是怎么登上google的。这是附件附件
这项研究是由以下机构支持:美国国家科学基金会许可证DCR8507256、和美国国防高级研究计划局(国防部),阿尔帕单号4871,由空间和海战系统司令部合同N00039-84-C-0089监控。↩
大多数属性继承模型有一个冲突解决规则来选择冲突的属性之一。我们选择不允许继承,因为我们无法找到一个例子是有道理的,除了当类型是相同的时候。另一方面,过程继承(下面讨论)使用了解决冲突的规则,因为存在着许多例子其中某个过程是优先的。↩
和POSTGRES的应用程序接口允许元组的数据流传回程序以具有动态变化的列和类型。↩
关系构造器实际上是聚合函数。我们设计了一个机制来支持可扩展的聚合函数,但尚未制定出查询语言的语法和语义。↩
我们使用了一个规则,类似于新的CommonLisp对象模型的规则[Boe86]。实际上比这里描述的略微复杂,这是为了防止一些麻烦的情况在继承层次结构中有环形的时候出现。↩
该查询使用QUEL风格的聚合函数。↩