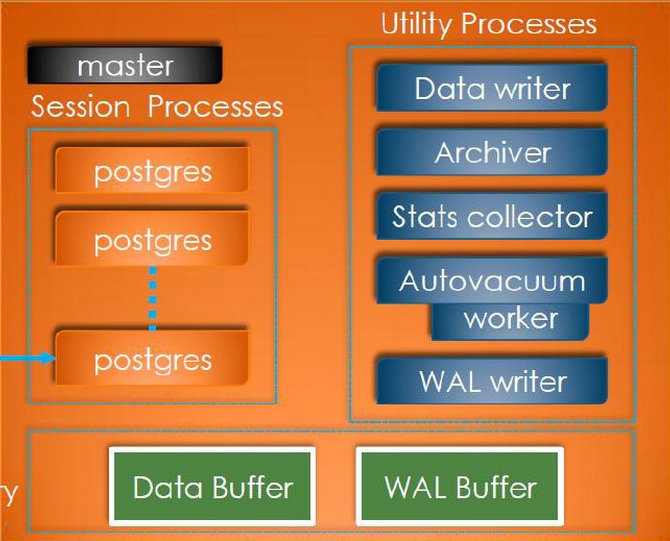
PostgreSQL的进程结构
PostgreSQL是一个多进程结构的系统,由master主进程fork出一系列子进程,这些进程包括数据库实例的后台进程,例如,Data Writer、Achiver等,也有服务client的session进程。大致结构图如下,
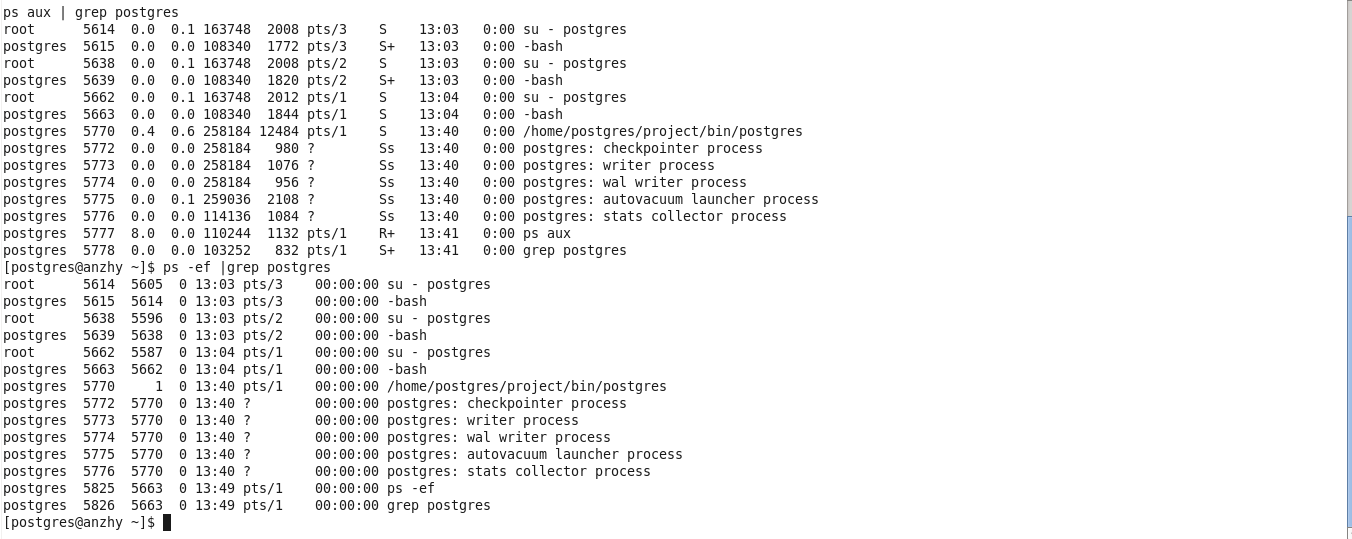
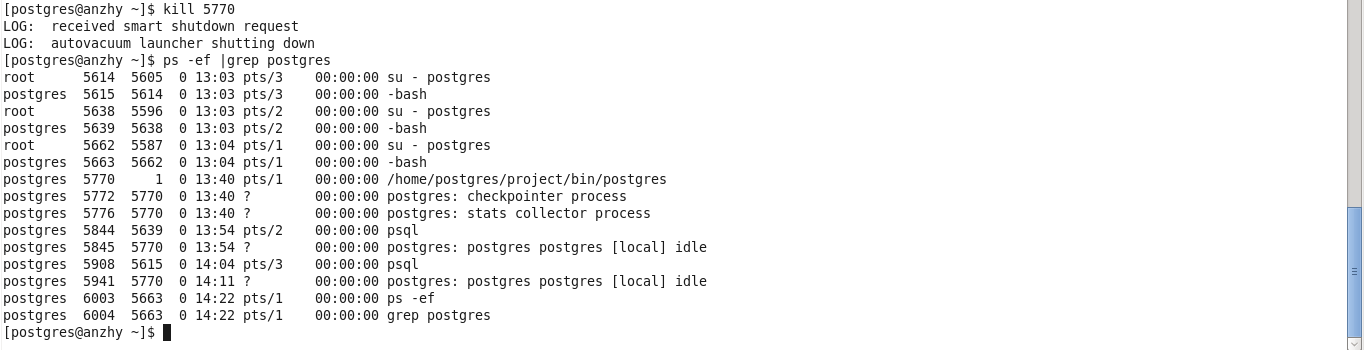
在Postgres启动之后,在没有client连接上来的时候,用ps可以看到其后台进程,如下
1
2
3
4
5
6
7
8
9
10
11
[postgres@anzhy ~]ps -ef | grep postgres
root 5662 5587 0 13 :04 pts/1 00 :00 :00 su - postgres
postgres 5663 5662 0 13 :04 pts/1 00 :00 :00 -bash
postgres 5770 1 0 13 :40 pts/1 00 :00 :00 /home/postgres/project/bin/postgres
postgres 5772 5770 0 13 :40 ? 00 :00 :00 postgres: checkpointer process
postgres 5773 5770 0 13 :40 ? 00 :00 :00 postgres: writer process
postgres 5774 5770 0 13 :40 ? 00 :00 :00 postgres: wal writer process
postgres 5775 5770 0 13 :40 ? 00 :00 :00 postgres: autovacuum launcher process
postgres 5776 5770 0 13 :40 ? 00 :00 :00 postgres: stats collector process
postgres 5825 5663 0 13 :49 pts/1 00 :00 :00 ps -ef
postgres 5826 5663 0 13 :49 pts/1 00 :00 :00 grep postgres
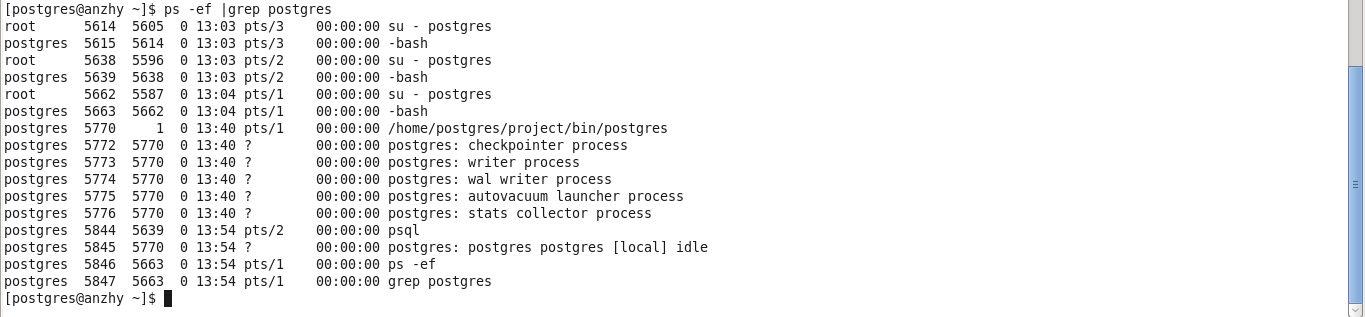
postgres(5770)进程就是master进程,可以看到,它有一些子进程都是以postgres:开头,这些子进程都是Postgres的后台进程。由于当前没有client连接,所以没有session进程。如果加入一个client连接,可以看到进程会多出一些,如下,
1
2
3
4
5
6
7
8
9
10
11
postgres 5663 5662 0 13 :04 pts/1 00 :00 :00 -bash
postgres 5770 1 0 13 :40 pts/1 00 :00 :00 /home/postgres/project/bin/postgres
postgres 5772 5770 0 13 :40 ? 00 :00 :00 postgres: checkpointer process
postgres 5773 5770 0 13 :40 ? 00 :00 :00 postgres: writer process
postgres 5774 5770 0 13 :40 ? 00 :00 :00 postgres: wal writer process
postgres 5775 5770 0 13 :40 ? 00 :00 :00 postgres: autovacuum launcher process
postgres 5776 5770 0 13 :40 ? 00 :00 :00 postgres: stats collector process
postgres 5844 5639 0 13 :54 pts/2 00 :00 :00 psql
postgres 5845 5770 0 13 :54 ? 00 :00 :00 postgres: postgres postgres [local] idle
postgres 5846 5663 0 13 :54 pts/1 00 :00 :00 ps -ef
postgres 5847 5663 0 13 :54 pts/1 00 :00 :00 grep postgres
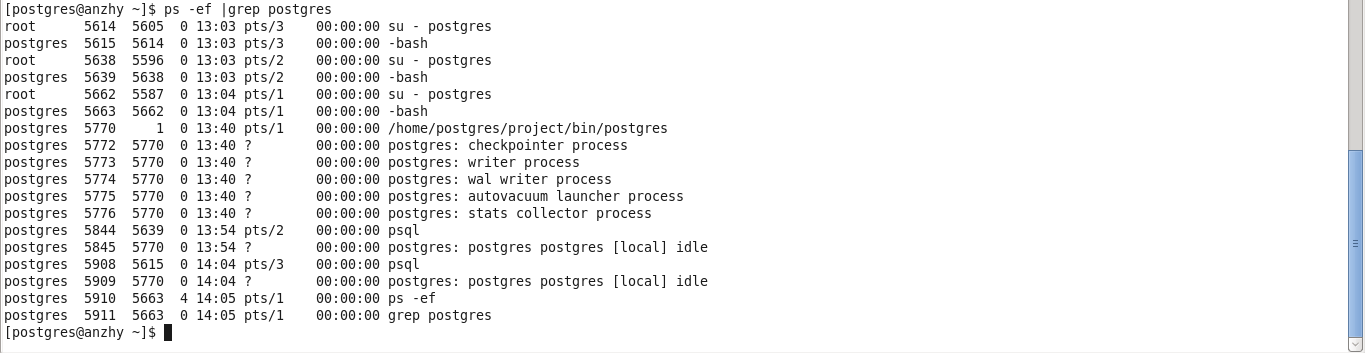
可以看到,psql进程(5844)连接Postgres之后,Postgres主进程fork了一个session子进程(5845)来服务这个client连接,如果又新增了一个client连接的话,那就会再多一个session子进程。如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
root 5662 5587 0 13 :04 pts/1 00 :00 :00 su - postgres
postgres 5663 5662 0 13 :04 pts/1 00 :00 :00 -bash
postgres 5770 1 0 13 :40 pts/1 00 :00 :00 /home/postgres/project/bin/postgres
postgres 5772 5770 0 13 :40 ? 00 :00 :00 postgres: checkpointer process
postgres 5773 5770 0 13 :40 ? 00 :00 :00 postgres: writer process
postgres 5774 5770 0 13 :40 ? 00 :00 :00 postgres: wal writer process
postgres 5775 5770 0 13 :40 ? 00 :00 :00 postgres: autovacuum launcher process
postgres 5776 5770 0 13 :40 ? 00 :00 :00 postgres: stats collector process
postgres 5844 5639 0 13 :54 pts/2 00 :00 :00 psql
postgres 5845 5770 0 13 :54 ? 00 :00 :00 postgres: postgres postgres [local] idle
postgres 5908 5615 0 14 :04 pts/3 00 :00 :00 psql
postgres 5909 5770 0 14 :04 ? 00 :00 :00 postgres: postgres postgres [local] idle
postgres 5910 5663 4 14 :05 pts/1 00 :00 :00 ps -ef
postgres 5911 5663 0 14 :05 pts/1 00 :00 :00 grep postgres
这次多出来的session进程是(5909),服务的client是(5908),可以看到所有的session进程也是以postgres:开头,并且进程名称中有[local]字样。因为Postgres是多进程结构,kill掉其中一个进程不会影响到其他进程。以kill掉(5909)进程为例说明如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
root 5662 5587 0 13 :04 pts/1 00 :00 :00 su - postgres
postgres 5663 5662 0 13 :04 pts/1 00 :00 :00 -bash
postgres 5770 1 0 13 :40 pts/1 00 :00 :00 /home/postgres/project/bin/postgres
postgres 5772 5770 0 13 :40 ? 00 :00 :00 postgres: checkpointer process
postgres 5773 5770 0 13 :40 ? 00 :00 :00 postgres: writer process
postgres 5774 5770 0 13 :40 ? 00 :00 :00 postgres: wal writer process
postgres 5775 5770 0 13 :40 ? 00 :00 :00 postgres: autovacuum launcher process
postgres 5776 5770 0 13 :40 ? 00 :00 :00 postgres: stats collector process
postgres 5844 5639 0 13 :54 pts/2 00 :00 :00 psql
postgres 5845 5770 0 13 :54 ? 00 :00 :00 postgres: postgres postgres [local] idle
postgres 5908 5615 0 14 :04 pts/3 00 :00 :00 psql
postgres 5937 5663 3 14 :10 pts/1 00 :00 :00 ps -ef
postgres 5938 5663 0 14 :10 pts/1 00 :00 :00 grep postgres
此时client的进程仍然处于活动状态,但是因为没有服务器端的session进程服务,运行sql的话会报错,提示连接已经断开,如下,
此时另一个client连接依然正常,可以正常执行sql,如下,
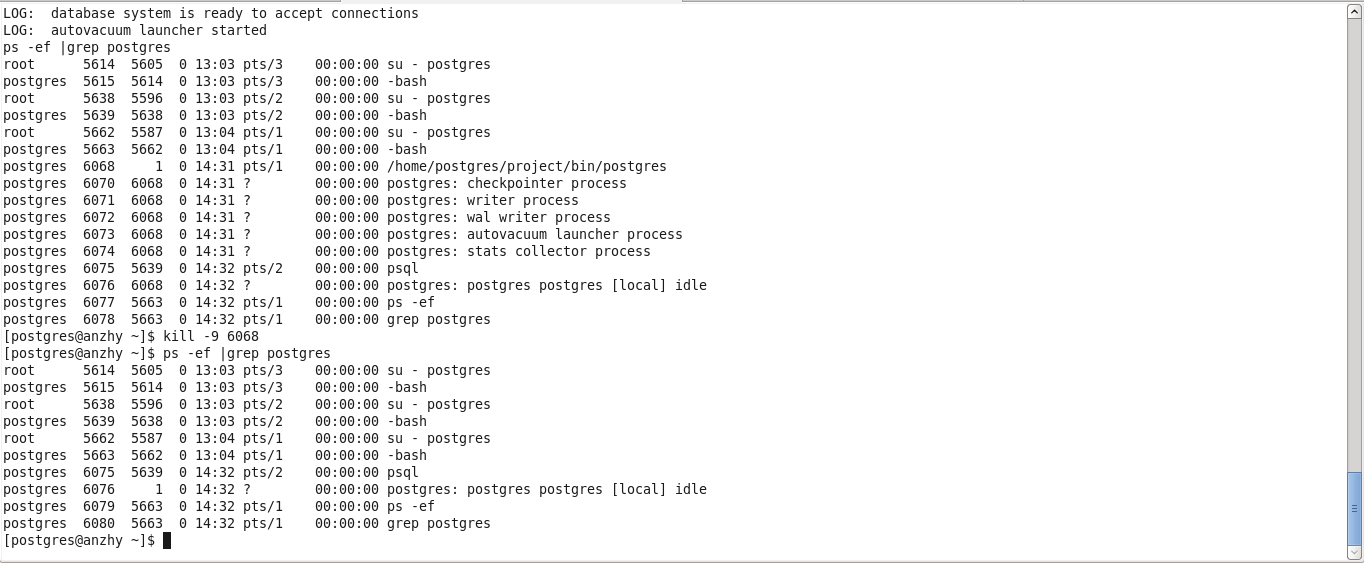
如果kill掉master主进程的话,其他现有的进程依然可以正常工作,但是已经无法再创建新的连接,因为子进程已经找不到可以fork的主进程,如下,
可以看到,虽然仍然有一些进程可以工作,但是,此时的系统是相当不稳定的,因为kill主进程的时候,autovacuum和writer进程在没有主进程的情况下也退出了。
如果用kill -9来杀死主进程的话,这样会杀死掉所有postgres的子进程,现象与上面的情况类似。如下,
此时的client连接仍然可以完成部分功能,原因是,虽然所有的后台进程在杀死主进程的时候已经被全部杀掉,但是服务client的session进程没有被杀掉,而是换了父进程为(1)的系统进程,继续为client提供服务。
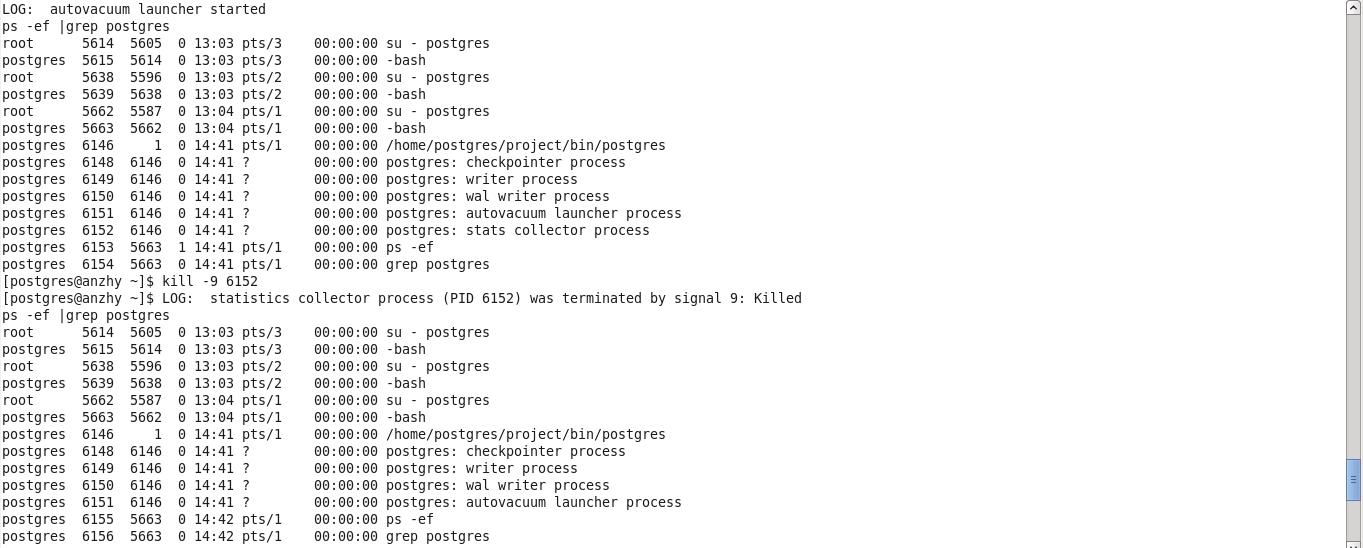
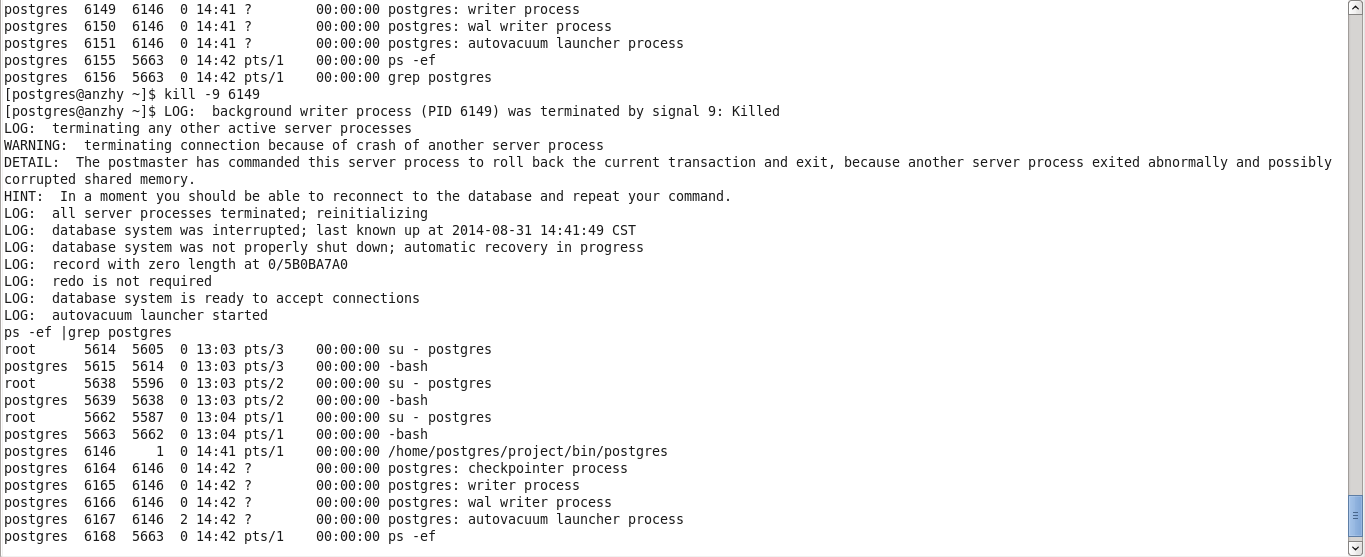
如果kill的不是主进程,而是后台子进程,系统会在必要的时候重新从主进程fork,这个特性可以在某些极端情况下,进程崩溃的时候,自动重启某些后台进程。在实验中发现,如果kill的是比较核心的进程,例如writer进程,系统会立刻重新fork所有后台子进程;而如果kill的是stats collector进程,如果当前没有client连接,那么不会立刻fork这个进程,在下次client连接的时候产生,如果当前有client连接,那么会立刻fork这个进程,其他进程都不受影响。如下图,
PostgreSQL的内存消耗
以上是PostgreSQL的进程结构,下面来看一下PostgreSQL的内存使用,以下实验参考了这里。
运行PostgreSQL之前,内存使用如下,
启动一个PostgreSQL数据库实例之后,内存使用如下,
启动一个本地psql的连接之后,内存使用如下,
切换psql到test数据库之后,内存使用如下,
建一个测试表test0之后,建表语句和内存使用如下,
1
2
test=# create table test0(id int );
CREATE TABLE
在test0中陆续insert大约100w(1048576个int类型)笔数据之后,内存使用如下,
从以上的操作来看,PostgreSQL的每个操作使用内存如下,
启动PostgreSQL
39M
连接PostgreSQL
2M
切换数据库
3M
建立测试表
-3M
insert数据
76M
可见,PostgreSQL启动所需的内存并不是很高,只有39M;新增一个连接所需的内存是2M;切换数据库所需的内存和建表所需的内存应该都很小,在本测试中应该是临时分配了一些内存然后又被收回了,所有会有3M和-3M这样的结论,当然,也有可能是后台其他进程的干扰;在插入100w笔数据之后,内存使用量增加了76M,插入的数据是1M个int,PostgreSQL中的int是4个byte,所以,实际上单纯这些数据占用的内存空间是4MB,其他是数据库产生的附属信息所需的空间。
drop测试表test0后,内存使用如下,
PostgreSQL没有立刻回收所有内存,而是只回收了37M,因此可以推测,大约33M(37M-4M)空间是数据的附属信息,剩下的39M(76M-37M)可能是和事务等其他系统特性相关信息的大小。
initdb过程分析
initdb过程是PostgreSQL安装之后初始化系统数据的过程,生成系统的数据字典和基础表。以9.3.4版本的PostgreSQL来分析。
initdb的主入口程序在src/bin/initdb/initdb.c,main函数在3481行,进入之后是先处理参数,之后开始处理各种设置,每个设置都是一个独立的函数,例如,setup_bin_paths是设置路径,set_info_version是设置版本信息。然后到了initialize_data_directory();,这是主要的处理函数,初始化数据库的数据目录。截取initialize_data_directory的部分代码片段如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
void
initialize_data_directory(void )
{
int i;
setup_signals();
umask(S_IRWXG | S_IRWXO);
create_data_directory();
create_xlog_symlink();
printf (_("creating subdirectories ... " ));
fflush(stdout);
for (i = 0 ; i < (sizeof (subdirs) / sizeof (char *)); i++)
{
if (!mkdatadir(subdirs[i]))
exit_nicely();
}
check_ok();
write_version_file(NULL);
set_null_conf();
test_config_settings();
setup_config();
bootstrap_template1();
上述代码最后的bootstrap_template1就是初始化template1库,截取bootstrap_template1的部分代码如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
* run the BKI script in bootstrap mode to create template1
*/
static void
bootstrap_template1(void )
{
PG_CMD_DECL;
char **line;
char *talkargs = "" ;
char **bki_lines;
char headerline[MAXPGPATH];
char buf[64 ];
printf (_("creating template1 database in %s/base/1 ... " ), pg_data);
fflush(stdout);
if (debug)
talkargs = "-d 5" ;
bki_lines = readfile(bki_file);
snprintf (headerline, sizeof (headerline), "# PostgreSQL %s\n" ,
PG_MAJORVERSION);
......
snprintf (cmd, sizeof (cmd),
"\"%s\" --boot -x1 %s %s %s" ,
backend_exec,
data_checksums ? "-k" : "" ,
boot_options, talkargs);
PG_CMD_OPEN;
for (line = bki_lines; *line != NULL; line++)
{
PG_CMD_PUTS(*line);
free (*line);
}
PG_CMD_CLOSE;
free (bki_lines);
check_ok();
其中用到了4个宏PG_CMD_DECL、PG_CMD_OPEN,PG_CMD_PUTS和PG_CMD_CLOSE,在initdb.c的开头部分有定义,如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#define PG_CMD_DECL char cmd[MAXPGPATH]; FILE *cmdfd
#define PG_CMD_OPEN \
do { \
cmdfd = popen_check(cmd, "w" ); \
if (cmdfd == NULL) \
exit_nicely(); \
} while (0 )
#define PG_CMD_CLOSE \
do { \
if (pclose_check(cmdfd)) \
exit_nicely(); \
} while (0 )
#define PG_CMD_PUTS(line ) \
do { \
if (fputs (line, cmdfd) < 0 || fflush(cmdfd) < 0 ) \
output_failed = true , output_errno = errno; \
} while (0 )
其实就是定义、打开、处理、关闭了一些文件。从bootstrap_template1的注释中可以得知,这个函数的作用是以bootstrap的方式来run一系列bki脚本,来建立template1。那么什么是bki呢?在PostgreSQL9.1的中文翻译文档中可以找到,第55章 。
后端接口(BKI)文件是一些用特殊语言写的脚本,这些脚本是 PostgreSQL 后端能够理解的,以特殊的 "bootstrap"(引导)模式运行,这种模式允许在不存在系统表的零初始条件下执行数据库函数,而普通的 SQL 命令要求系统表必须存在。因此 BKI 文件可以用于在第一时间创建数据库系统。(可能除此以外也没有其它用处。)
该文档后面还给出了一些bki文件语法的示例。在创建一个新的数据库集群时,initdb使用BKI文件 来完成部分工作。initdb使用的文件是作为编译 PostgreSQL的一部分,由一个叫genbki.pl的程序(src/backend/catalog/genbki.pl)创建, 这个程序读取源代码树目录的src/include/catalog/目录里的几个特殊C开头的文件。生成的BKI文件叫postgres.bki, 并且通常安装在安装目录里的share子目录。
genbki.pl是一个perl程序,程序的末尾有一段简短的说明,如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
sub usage
{
die <<EOM;
Usage: genbki.pl [options] header...
Options:
-I path to include files
-o output path
--set-version PostgreSQL version number for initdb cross-check
genbki.pl generates BKI files from specially formatted
header files. These BKI files are used to initialize the
postgres template database.
Report bugs to <pgsql-bugs\@postgresql .org>.
EOM
}
postgres.bki是用genbki.pl创建的,创建后一般在PostgreSQL安装目录的$POSTGRESQLHOME/share目录下。,参数是catalog.pm。参考bki文档的描述,其输入命令格式有以下一些,
create [bootstrap] [shared_relation] [without_oids] tablename tableoid (name1 = type1 [, name2 = type2, ...])
创建一个叫做 tablename,OID 为 tableoid 的表,表字段在圆括弧中给出。 bootstrap.c 直接支持下列字段类型: bool,bytea,char (1 字节), name,int2,int4, regproc,regclass, regtype,text,oid, tid,xid, cid,int2vector,oidvector, _int4 (数组),_text (数组), _aclitem(数组)。尽管我们可以创建包含其它类型字段的表, 但是我们只有在创建完 pg_type 并且填充了合适的记录之后才行。 (这实际上就意味着在系统初始化表中,只能使用这些字段类型,而非系统初始化表可以使用任意内置类型。) 如果声明了 bootstrap,那么改表将只在磁盘上创建; 不会向 pg_class,pg_attribute 等系统表里面输入任何东西。 因此这样的表将无法被普通的 SQL 操作访问,直到那些记录用硬办法(用 insert 命令)填入。 这个选项用于创建 pg_class 等自身。 如果声明了 shared_relation,那么表就作为共享表创建。 除非声明了 without_oids,否则将会有 OID。
打开一个名为 tablename 的表,准备插入数据。任何当前已经打开的表都会被关闭。
关闭打开的表。给出的表明是用于交叉检查,但并不是必须的。 》 * insert [OID = oid_value] (value1 value2 ...) 用 value1, value2, 等作为字段值以及 oid_value 作为其 OID(对象标识)向打开的表插入一条新记录,如果 oid_value 为零(0),否则省略了改子句,而表则拥有 OID,并赋予下一个可用的 OID 数值。NULL 可以用特殊的关键字 _null_声明。包含空白的值必须用双引号栝起。
declare [unique] index indexname indexoid on tablename using amname ( opclass1 name1 [, ...] )
在一个叫 tablename 的表上用 amname 访问方法创建一个 OID 是 indexoid 的叫做 indexname 的索引。 索引的字段叫 name1,name2 等,而使用的操作符表分别是 opclass1,opclass2 等。 将会创建索引文件和恰当的系统表记录,但是索引内容不会被此命令初始化。
填充前面声明的索引。
系统初始化的bki文件(postgres.bki)结构是有一个比较特殊的规定。因为,open 命令打开的表需要系统事先存在另外一些基本的表, 在这些表存在并拥有数据之前,我们不能使用 open 命令。 (这些最低限度必须存在的表是 pg_class,pg_attribute, pg_proc,和 pg_type。) 为了允许这些表自己被填充,带着 bootstrap 选项的 create 隐含打开所创建的表用于插入数据。因此,postgres.bki 文件的结构必须是这样的,
create bootstrap 其中一个关键表
insert 数据,这些数据至少描述这些关键表本身
close
重复创建和填充其它关键表。
create (不带 bootstrap)一个非关键表
open
insert 需要的数据
close
重复创建其它非关键表。
定义索引。
build indices
当然,肯定还有其它未记录文档的顺序依赖关系。
initdb.c代码中,for循环中的PG_CMD_PUTS就是在处理bki文件的每一行。下面看一个postgres.bki中的真实例子来说明其结构。文件的最开头是如下语句,
1
2
3
4
5
6
7
8
9
10
11
12
create pg_proc 1255 bootstrap rowtype_oid 81
(
proname = name ,
pronamespace = oid ,
proowner = oid ,
prolang = oid ,
procost = float4 ,
prorows = float4 ,
provariadic = oid ,
protransform = regproc ,
......
表示创建名为pg_proc的表,由于带了bootstrap,该表是一个关键表,这也表明关键表一定要优先创建的原则。括号里面的内容是每一个列的信息。接下去是一系列的insert OID,在大约2454行出现了关闭pg_proc,如下,
1
2
3
4
5
......
insert OID = 3473 ( spg_range_quad_leaf_consistent 11 10 12 1 0 0 0 f f f f t f i 2 0 16 "2281 2281" _null_ _null_ _null_ _null_ spg_range_quad_leaf_consistent _null_ _null_ _null_ )
insert OID = 3566 ( pg_event_trigger_dropped_objects 11 10 12 10 100 0 0 f f f f t t s 0 0 2249 "" "{26,26,23,25,25,25,25}" "{o,o,o,o,o,o,o}" "{classid, objid, objsubid, object_type, schema_name, object_name, object_identity}" _null_ pg_event_trigger_dropped_objects _null_ _null_ _null_ )
close pg_proc
......
接下去的步骤也比较类似,接下去处理的是关键表pg_type,pg_attribute,pg_class。再后面处理的就不是关键表了,而是非关键表pg_attrdef,如下,
1
2
3
4
5
6
7
8
9
create pg_attrdef 2604
(
adrelid = oid ,
adnum = int2 ,
adbin = pg_node_tree ,
adsrc = text
)
open pg_attrdef
close pg_attrdef
可以很明显的发现非关键表比关键表多了open动作,但是因为这个表没有数据,所以跳过了insert动作。很多非关键表都在这里跳过了insert动作,例如后续的pg_constraint,pg_inheris,pg_index等,但也有一些表需要在open之后有insert动作,例如,pg_operator,pg_opfamily,pg_opclass等。之后就一系列非关键表的创建,大约在5421行出现了declare语句,如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
declare toast 2830 2831 on pg_attrdef
declare toast 2832 2833 on pg_constraint
declare toast 2834 2835 on pg_description
declare toast 2836 2837 on pg_proc
declare toast 2838 2839 on pg_rewrite
declare toast 3598 3599 on pg_seclabel
declare toast 2840 2841 on pg_statistic
declare toast 2336 2337 on pg_trigger
declare toast 2846 2847 on pg_shdescription
declare toast 2966 2967 on pg_db_role_setting
declare unique index pg_aggregate_fnoid_index 2650 on pg_aggregate using btree(aggfnoid oid_ops)
declare unique index pg_am_name_index 2651 on pg_am using btree(amname name_ops)
declare unique index pg_am_oid_index 2652 on pg_am using btree(oid oid_ops)
declare unique index pg_amop_fam_strat_index 2653 on pg_amop using btree(amopfamily oid_ops, amoplefttype oid_ops, amoprighttype oid_ops, amopstrategy int2_ops)
从这里开始定义索引,然后就是一系列的定义索引,最后一行是5526行build indices,如下,
1
2
3
4
5
declare unique index pg_shseclabel_object_index 3593 on pg_shseclabel using btree(objoid oid_ops, classoid oid_ops, provider text_ops)
declare unique index pg_extension_oid_index 3080 on pg_extension using btree(oid oid_ops)
declare unique index pg_extension_name_index 3081 on pg_extension using btree(extname name_ops)
declare unique index pg_range_rngtypid_index 3542 on pg_range using btree(rngtypid oid_ops)
build indices
从以上的分析,我们已经可以大致掌握住initdb过程的关键,就是产生和执行postgres.bki。其他部分都是一些参数检查,文件操作等辅助功能。